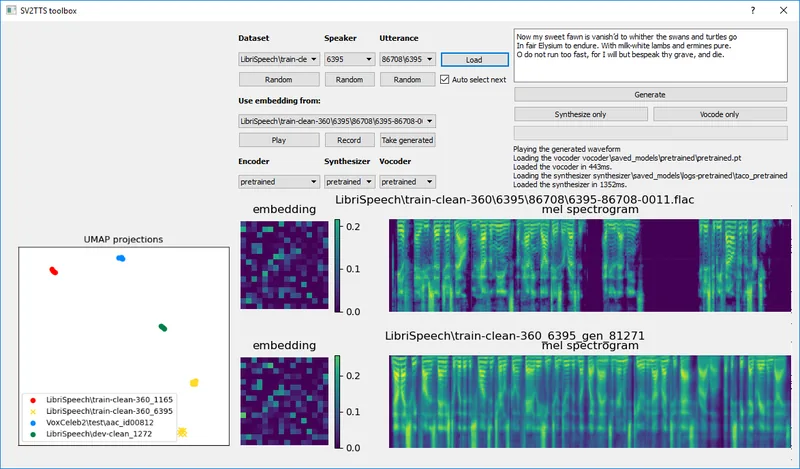
概要
このリポジトリは、数秒の音声から声の特徴を学習し、任意のテキストをリアルタイムでその声で話すことができるSV2TTS(話者検証からマルチスピーカーテキスト読み上げ合成への転移学習)のオープンソース実装です。
ディープラーニングに基づく3段階のフレームワークで、声のクローン作成と合成を可能にします。
WindowsおよびLinux環境で動作し、NVIDIA GPUまたはCPUを利用してCLIおよびGUIツールボックスとして使用できます。
研究者、開発者、またはリアルタイム音声合成技術に関心のあるユーザーに適していますが、本技術は最新のものではないとされており、より高品質な代替案も提示されています。
互換性・特徴
- Python
- CLI
- GUI
- GPU対応
- Windows対応
- Linux対応
基本情報
| ライセンス | NOASSERTION |
| Stars | 59,960 |
| Forks | 9,401 |
| カテゴリ | 音声生成 / TTS |
| アクティビティ | mid |
最新のissue
- zhang voice (更新: 2026-06-25)
- 糖尿病性足病変の男性が本日亡くなりました (更新: 2026-06-05 / Aman with diabetic foot has passed today)
- このプロジェクトはリアルタイム音声通話に使えますか? (更新: 2026-03-16 / can i use this project for real time voice call ?)
- 有料でアラビア語を追加 (更新: 2026-03-07 / Add Arabic language for a fee)
- ImportError: libtorch_cpu.so: 共有オブジェクトに必要な実行可能スタックを有効にできません: 無効な引数 (更新: 2026-01-26 / ImportError: libtorch_cpu.so: cannot enable executable stack as shared object requires: Invalid argument)
GitHub: https://github.com/CorentinJ/Real-Time-Voice-Cloning