概要
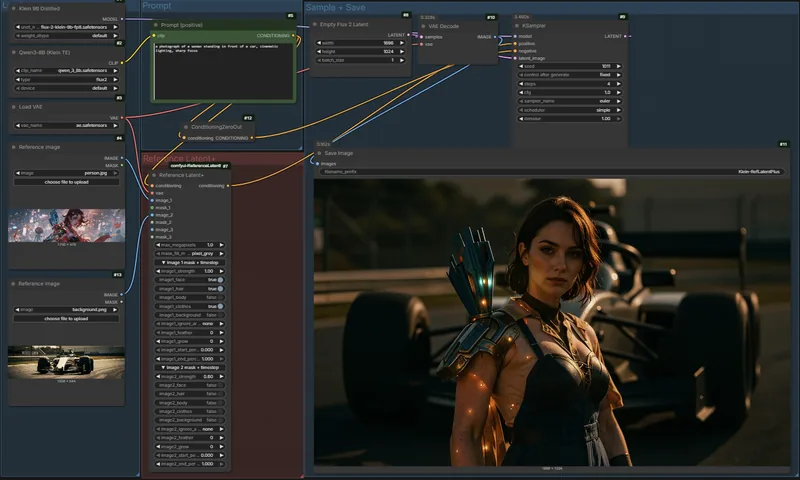
このツールはComfyUIの標準`ReferenceLatent`ノードを強化したドロップイン代替品です。
画像ごとに参照強度、タイムステップ範囲、MediaPipeによる顔・体・背景などの自動マスク、およびアテンションコストを抑えるメガピクセル制限をきめ細かく制御できます。
最大4枚の参照画像を1つのノードで扱え、VAEエンコードもノード内で完結するため、複雑なワークフローを簡素化します。
Flux、Klein、Lumina、Hunyuanなどの`reference_latents`を利用する幅広いモデルに対応しており、より高度な画像生成制御を求めるComfyUIユーザーに最適です。
互換性・特徴
- ComfyUI対応
- 画像生成AI
- Python
- GPU必須
- MediaPipe対応
- AI/ML
基本情報
| Stars | 28 |
| Forks | 4 |
| カテゴリ | 画像生成 |
| アクティビティ | low |
最新のissue
- Klein 9bとは完璧に動作するが、qwenやzimageとは全く動作しない。 (更新: 2026-06-07 / Works perfectly with Klein 9b but aboslutely not with qwen or zimage.)
- 参照画像の最大数を9に設定。一部のワークフローで必要です。 (更新: 2026-05-08 / pls set maximum ref images to 9, some workflow need it)
GitHub: https://github.com/shootthesound/comfyui-ReferenceLatentPlus