
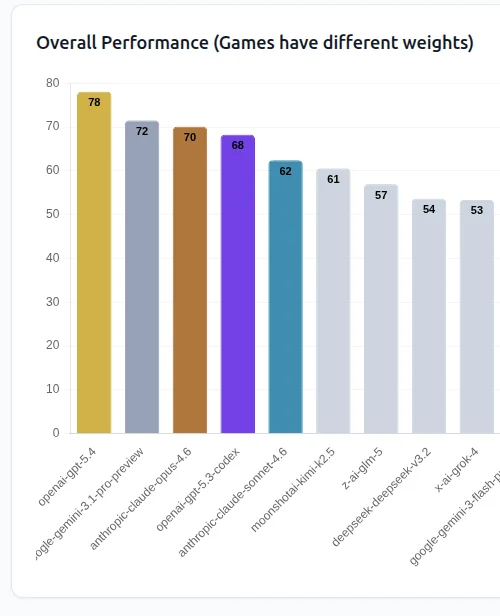
Game Agent Coding Leagueの2026年3月結果で、OpenAIのGPT-5.4が総合78.07点で首位となりました。
同リーグは、各モデルがゲームを直接プレイするのではなく、7種類のゲームを戦うエージェントコードを生成して順位を競う形式です。
GPT-5.4が首位となったGACLの順位
公開リーダーボードでは、2位がGoogle Gemini 3.1 Pro Previewの71.50点、3位がAnthropic Claude Opus 4.6の70.08点でした。
4位にはOpenAI GPT-5.3-Codexが68.27点で入り、5位はClaude Sonnet 4.6の62.41点です。
オープンウェイト系ではMoonshot AIのKimi K2.5が6位、Z.aiのGLM-5が7位に位置しました。
Game Agent Coding Leagueの評価方法
各モデルは2体のエージェントを生成し、同一モデルのペアを除く他モデルのエージェントと総当たりで対戦します。
ランキングには各モデルのうち成績が高かった1体のみが採用されます。
投稿者によると、BattleshipではGPT系が強さを見せた一方で、Tic-Tac-Toeは差がつきにくく、次回以降は別ゲームへの置き換えを検討しているとのことです。
Redditで出た反応
Redditでは、GPT-5.4やGPT-5.3-Codexの順位を評価し、コーディング系のエージェント生成でOpenAI勢が優位だと受け止める声がありました。
その一方で、ゲーム特化ベンチマークの結果が実務性能をそのまま示すとは限らないとして、統計の妥当性を疑問視する意見も見られます。
特定分野ではClaudeや他社モデルのほうが強いという指摘もあり、用途別評価の必要性を挙げる投稿が続きました。
参考リンク:

