概要
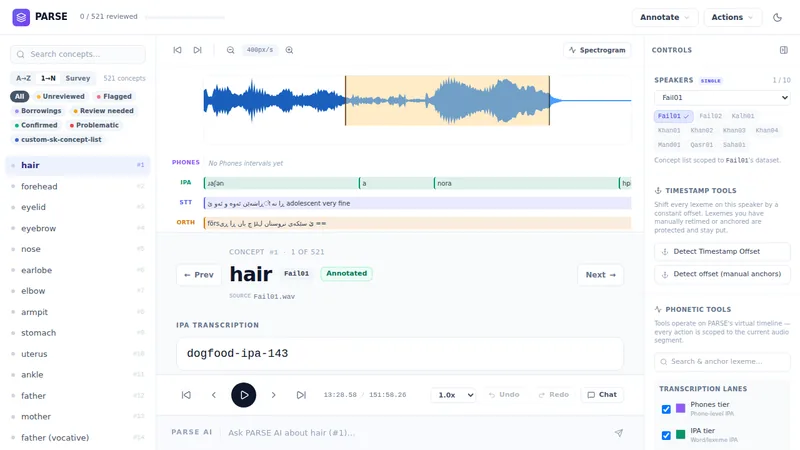
PARSEは、記述言語学のフィールドワークと、それに続く比較分析を支援するブラウザベースのワークステーションです。
録音された音声の転写、正確なタイムスタンプ管理、話者間の語彙形式比較、借用証拠の追跡、そしてクリーンなデータセットのエクスポートといった一連の作業を、統合されたワークスペースで効率的に行えます。
主要な特徴としては、階層的なIPA/正書法注釈機能、話者間の同系語(cognate)判定や借用検出機能、LingPyおよびNEXUS形式でのデータエクスポート、そしてAI支援による音声テキスト変換(STT)が挙げられます。
想定ユーザーは、長時間の録音、単語リスト、複数の話者や方言を扱うフィールドワークの言語学者、比較言語学者、歴史言語学者、および言語ドキュメンテーションチームです。
互換性・特徴
- Web UI
- Python
- React
- AI支援
- 言語学ツール
- データエクスポート
基本情報
| ライセンス | MIT |
| Stars | 5 |
| カテゴリ | ASR / 音声認識 |
| アクティビティ | low |
最新のissue
- コンセプト層クリップが誤リンク(レガシー由来)、アノテーション保存に同時実行ガードがなくサイレント上書き (更新: 2026-06-01 / Concept-tier clips mis-linked to wrong concept (legacy/source origin) + no concurrency guard on annotation saves (silent clobber))
- 機能: BEAUti同等のBEAST2解析設定メニュー (エクスポート前欠損データチェック付き) (更新: 2026-06-01 / Feature: BEAUti-equivalent BEAST2 analysis settings menu (+ pre-export missing-data check))
- 機能: 統計的音韻対応の推論機能 (SIL Cog) (更新: 2026-05-30 / Feature: Statistical sound-correspondence inference (SIL Cog))
- 機能: 諸変種間の関連性ネットワークグラフと地理的方言地図 (SIL Cog) (更新: 2026-05-30 / Feature: Variety-relatedness network graphs & geographic dialect maps (SIL Cog))
- 機能: 階層的クラスタリングおよびツリー可視化 – UPGMA / Neighbor-Joining (SIL Cog) (更新: 2026-05-30 / Feature: Hierarchical clustering & tree visualization – UPGMA / Neighbor-Joining (SIL Cog))