概要
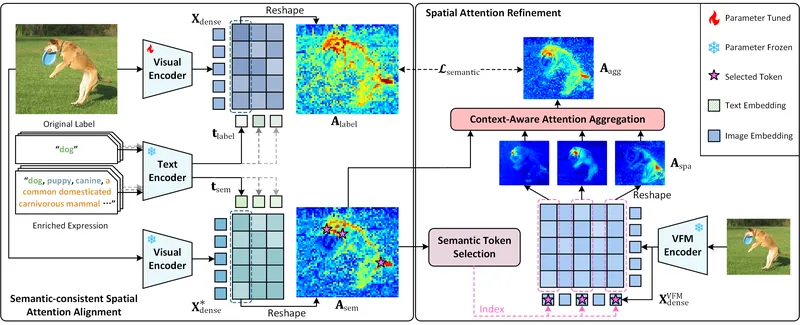
SynCLIPは、セマンティクス的に同等な表現でも空間的注意が異なるという、オープンボキャブラリー高密度知覚(OVDP)における課題を解決する言語-画像事前学習フレームワークです。
同義語に起因するグラウンディングの不整合性を解消し、より堅牢な知覚を実現します。
SSAモジュールで注意マップの一貫性を高め、SARモジュールで空間的関連領域を精密化します。
また、同義語で強化された視覚コーパスSEViCも活用。
CVPR 2026で採択されたこの手法は、CLIPベースのOVDPにおいて最先端の性能を発揮します。
コンピュータビジョン、特にOVDPや言語-画像事前学習の研究者・開発者向けです。
互換性・特徴
- Python
- GPU必須
- 研究用途
- コンピュータビジョン
- 言語-画像事前学習
- CLIPベース
基本情報
| ライセンス | Apache-2.0 |
| Stars | 8 |
| カテゴリ | マルチモーダル |
| アクティビティ | low |