概要
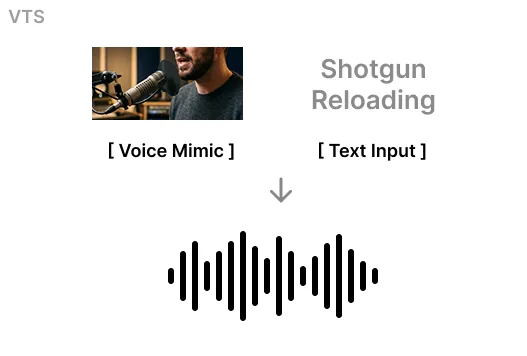
VTS(Voice To Sound)は、ユーザーの音声スケッチとテキストプロンプトを組み合わせて効果音を生成するツールです。
言葉では表現しにくい音のニュアンスを声で伝え、テキストで意図を補足することで、直感的かつ正確なサウンドデザインを可能にします。
サウンドデザイナーや開発者など、効果音の指定や生成に課題を持つユーザーを対象とし、約10.7億パラメータのlatent diffusionモデルを基盤に、高品質な効果音を提供します。
互換性・特徴
- Python
- CLI
- GPU必須
- Hugging Face
基本情報
| ライセンス | MIT |
| Stars | 32 |
| Forks | 3 |
| カテゴリ | 音声生成 / TTS |
| アクティビティ | low |
最新のissue
- 出力音声が意味不明 (更新: 2026-06-02 / nonsensical output audio)
GitHub: https://github.com/thxxx/VTS