概要
EVA(Efficient Video Agent)は、動画エージェントのための効率的な強化学習フレームワークです。
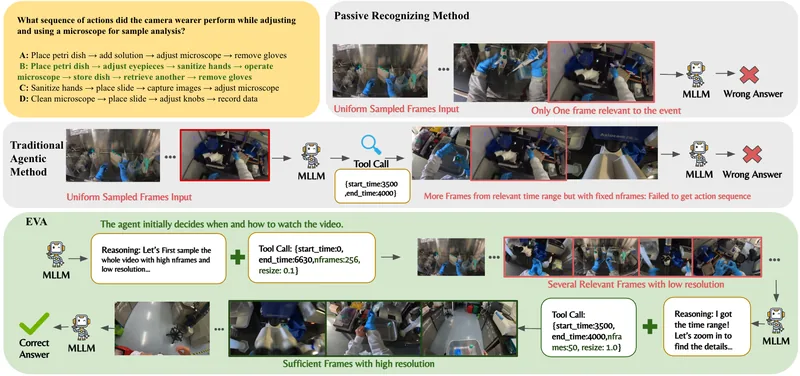
このモデルは「planning-before-perception」という独自のアプローチを採用しており、エージェントが自律的に「何を」「いつ」「どのように」視聴するかを決定し、クエリ駆動型で効率的な動画理解を実現します。
反復的な要約・計画・行動・反省の推論を通じて、受動的な認識器とは異なり、能動的に動画コンテンツを解析します。
主に動画理解、強化学習、AIエージェント分野の研究者や開発者、特に大規模な動画データからの効率的な情報抽出に関心のあるユーザーを対象としています。
互換性・特徴
- Python
- GPU必須
- Hugging Face
- CLI
基本情報
| Stars | 26 |
| カテゴリ | マルチモーダル |
| アクティビティ | low |
最新のissue
- 訓練コード (更新: 2026-06-19 / train code)
- オーディオ (更新: 2026-06-02 / audio)
- Hugging FaceでEVAトレーニングデータセットを公開 (更新: 2026-03-25 / Release EVA training datasets on Hugging Face)