概要
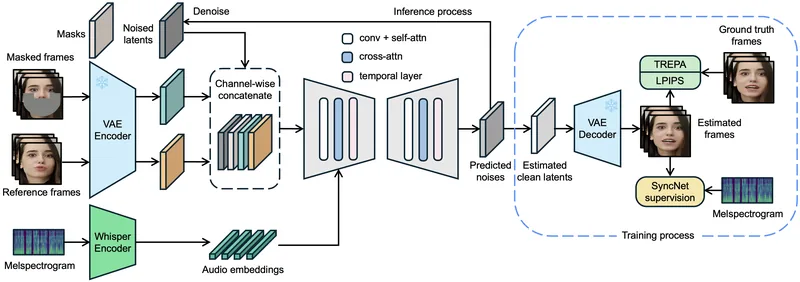
LatentSyncは、音声入力に基づいて動画のリップシンクを生成する、エンドツーエンドの革新的な手法です。
既存のピクセル空間拡散や2段階生成アプローチとは異なり、オーディオ条件付き潜在拡散モデルと強力なStable Diffusionの能力を統合し、複雑な音響視覚相関を直接学習します。
512×512解像度でのトレーニングにより画質のぼやけを軽減し、時間的な一貫性を向上させ、中国語動画に対するパフォーマンス強化、そしてVRAM要件の最適化が図られています。
高品質かつ自然な動画リップシンクを求めるクリエイターや研究者にとって、強力なツールとなるでしょう。
互換性・特徴
- Python
- Diffusion Model
- GPU必須
- Hugging Face対応
- 動画処理
基本情報
| ライセンス | Apache-2.0 |
| Stars | 5,776 |
| Forks | 947 |
| カテゴリ | 画像生成 |
| アクティビティ | mid |
最新のissue
- 5090D 32G VRAMでの二段階学習における、学習効果を保証する効果的な方法 (更新: 2026-05-09 / 关于5090D 32G显存训练二阶段,如何有效保证训练效果)
- PyTorchのバージョンが低いため、50シリーズGPUでの実行が不可能 (更新: 2026-04-29 / 因为pytorch版本太低,无法在50系显卡上运行)