概要
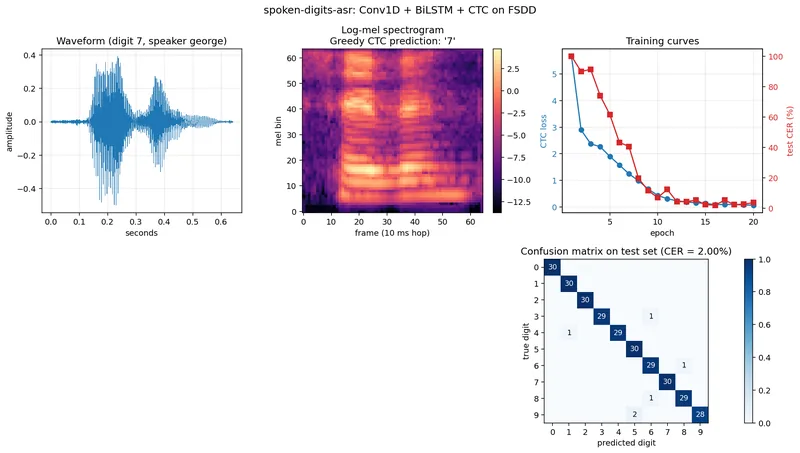
本プロジェクトは、Free Spoken Digit Datasetを用いてゼロから訓練された小型のCTC音声認識器です。
1秒間の数字音声(0~9)のWAVファイルを高精度(98%)で文字起こしする機能を提供します。
大規模な音声認識システムが「メル特徴量、シーケンスエンコーダ、CTCヘッド」といった基本的な構成要素から成り立っていることを、実際に手を動かして理解することを目的としています。
ラップトップのCPUでわずか約90秒で訓練が完了するため、音声認識の基礎やニューラルネットワークの仕組みを実践的に学びたい開発者や研究者に最適なツールです。
互換性・特徴
- Python
- PyTorch
- CLI
- 音声認識
- CPU動作
- 研究・学習用
基本情報
| ライセンス | MIT |
| Stars | 1 |
| カテゴリ | ASR / 音声認識 |
| アクティビティ | low |