概要
CPPO(Contrastive Perception Policy Optimization)は、視覚言語モデル(VLM)エージェントのファインチューニングを目的とした強化学習フレームワークです。
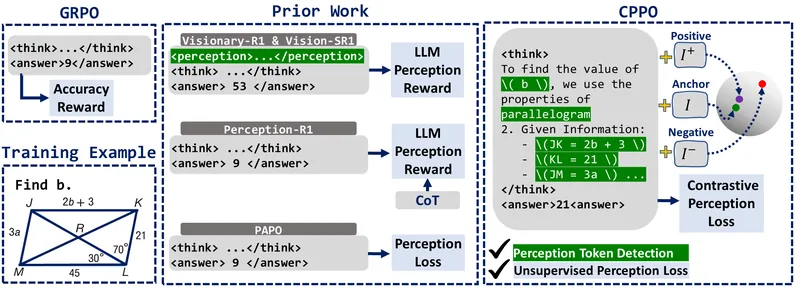
外部からの監視なしで、対比的知覚トレーニングを通じてVLMの知覚能力を向上させ、複雑なマルチモーダル推論タスクで一貫した性能向上を実現します。
エントロピーベースの知覚トークン検出と対比的知覚損失(CPL)を強化学習と統合し、研究準備済みの実装、前処理、トレーニング、評価パイプラインを提供。
Hugging Faceで事前学習済みモデルも公開されており、VLMの性能向上や強化学習を用いたエージェント開発に取り組む研究者や開発者向けです。
互換性・特徴
- Python
- 強化学習
- VLM
- Hugging Face
- 研究フレームワーク
基本情報
| Stars | 9 |
| カテゴリ | マルチモーダル |
| アクティビティ | low |
GitHub: https://github.com/vbdi/cppo