概要
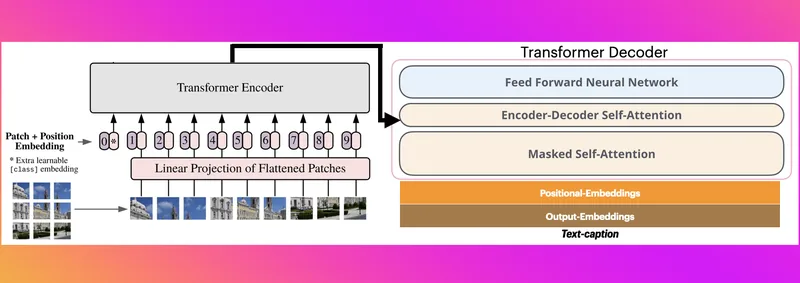
`nlpconnect/vit-gpt2-image-captioning` は、画像を入力すると英語の説明文を自動生成できる画像キャプション生成モデルです。
ViT を画像エンコーダ、GPT-2 をテキストデコーダとして組み合わせ、Hugging Face Transformers からそのまま読み込めます。
Pythonコードで個別実装する方法に加え、`pipeline("image-to-text")` による簡単な利用例もあり、画像理解の試作、AIアプリ開発、研究・検証を進めたい開発者や機械学習利用者に向いています。
互換性・特徴
- Python
- Transformers
- PyTorch
- 画像キャプション生成
- CLI
- GPU対応
基本情報
| ライセンス | apache-2.0 |
| Likes | 931 |
| Downloads | 65,045 |
| Pipeline | image-to-text |
| カテゴリ | マルチモーダル |
| アクティビティ | mid |
HuggingFace: https://huggingface.co/nlpconnect/vit-gpt2-image-captioning