概要
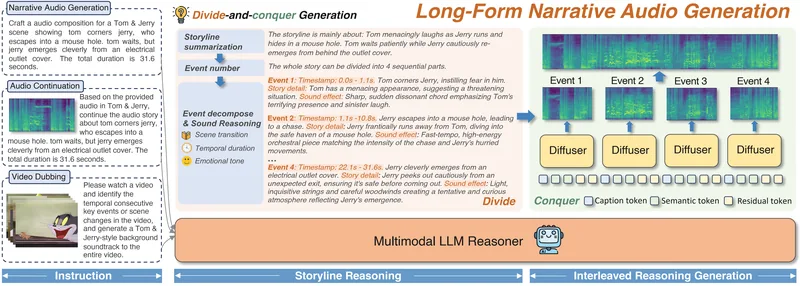
AudioStoryは、大規模言語モデル(LLM)とText-to-Audio (TTA) システムを統合し、長尺の物語音声生成を可能にする統一フレームワークです。
動画の吹き替え、音声の継続、および複雑な物語音声の合成に対応し、時間的コヒーレンスと感情的トーンの一貫性を保ちます。
LLMが複雑な指示を分解し、文脈に応じたサブタスクに変換することで、強力な指示追従能力を発揮します。
モジュール式のトレーニングパイプラインを不要にするエンドツーエンドの学習と、イベント内セマンティックアラインメントとイベント間一貫性を維持するデカップリングされたブリッジングメカニズムが特徴です。
音声コンテンツの制作者や研究者向けに、長尺の高品質なナラティブオーディオを生成する革新的なツールです。
互換性・特徴
- LLM連携
- Text-to-Audio
- Python
- 研究用
- CLI
- GPU必須
基本情報
| Stars | 302 |
| Forks | 22 |
| カテゴリ | 音声生成 / TTS |
| アクティビティ | mid |
最新のissue
- 動画Dubbingの実装詳細と使用方法に関する問い合わせ (更新: 2025-09-05 / Inquiry about Video Dubbing Implementation Details and Usage)
- AudioStory artifacts (モデル, データセット) をHugging Faceで公開 (更新: 2025-09-02 / Release AudioStory artifacts (models, dataset) on Hugging Face)
- /group/40034/gloriayxguo/AudioStory_open とは何ですか? (更新: 2025-09-02 / whats this /group/40034/gloriayxguo/AudioStory_open)