概要
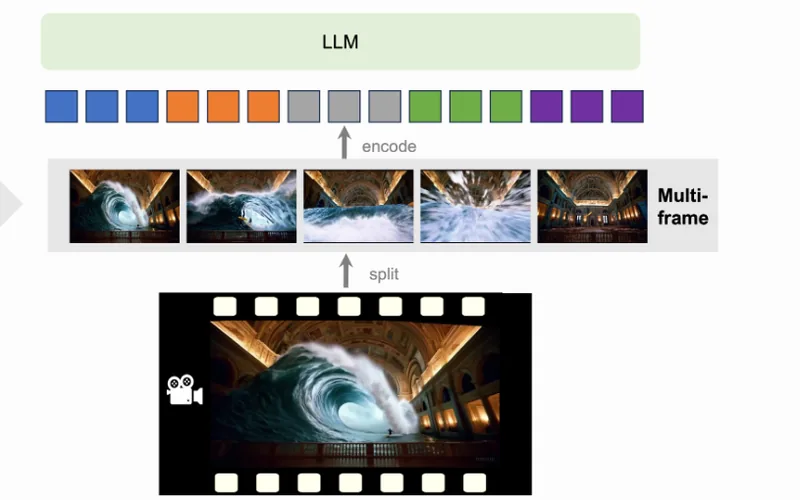
LLaVA-NeXT-Video-7B-hfは、画像と動画を一緒に理解して対話できるオープンソースのマルチモーダル生成モデルです。
Transformers経由でPythonから利用でき、複数の画像・動画入力やチャット形式プロンプトに対応します。
動画はフレーム抽出して扱い、内容説明、質問応答、要約、映像理解タスクに向きます。
主にGPU環境の開発者や研究者、映像AIを試したい実装者向けで、4bit量子化やFlash-Attention 2による高速化も案内されています。
互換性・特徴
- GPU必須
- Python
- Transformers
- 動画理解
- 画像入力対応
- CLI
基本情報
| ライセンス | llama2 |
| Likes | 125 |
| Downloads | 156,094 |
| Pipeline | video-text-to-text |
| カテゴリ | マルチモーダル |
| アクティビティ | mid |
HuggingFace: https://huggingface.co/llava-hf/LLaVA-NeXT-Video-7B-hf