概要
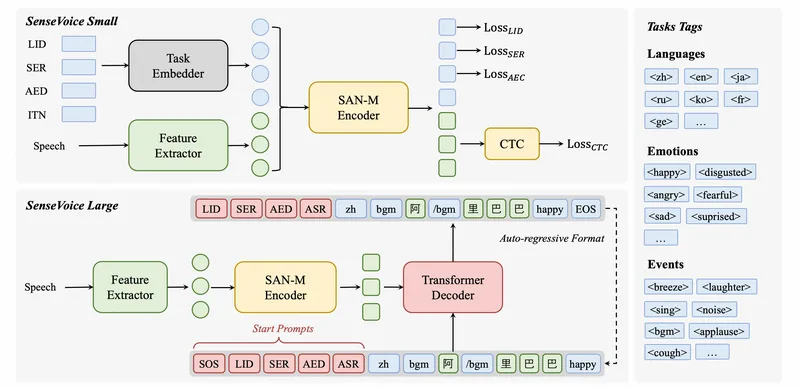
SenseVoiceは、自動音声認識(ASR)、話者言語識別、音声感情認識、音声イベント検出、そして最新のアップデートでは話者分離までをカバーする多機能な音声基盤モデルです。
50以上の言語に対応し、40万時間以上のデータで訓練されており、Whisperモデルを凌駕する高精度を誇ります。
非自己回帰型のエンドツーエンドフレームワークにより、Whisper-Largeの15倍高速な推論速度を実現し、わずか70msで10秒の音声を処理可能です。
BGM、拍手、笑い、泣き、咳、くしゃみなどの音声イベント検出や優れた感情認識能力も持ち合わせています。
開発者向けにファインチューニングスクリプトやサービス展開パイプラインも提供されており、Python、C++、HTML、Java、C#といった多様なクライアント言語に対応。
多言語の音声を高速かつ高精度に分析したい研究者や開発者に最適なツールです。
互換性・特徴
- Python
- 多言語対応
- 高速推論
- ONNX対応
- HuggingFace対応
- CLI
基本情報
| ライセンス | NOASSERTION |
| Stars | 8,595 |
| Forks | 784 |
| カテゴリ | ASR / 音声認識 |
| アクティビティ | high |
最新のissue
- VAD + CAM++ speaker model + punctuation model 使用時に結果が空で返される (更新: 2026-06-10 / 使用VAD + CAM++ speaker model + punctuation model 返回结果是空的)
最新リリース: v1.0.0: SenseVoice — Multilingual Speech Understanding (2026-05-25)