概要
このツールは、Google Deepmindが開発した効率的な並列オーディオ生成モデル「SoundStorm」をPyTorchで実装したものです。
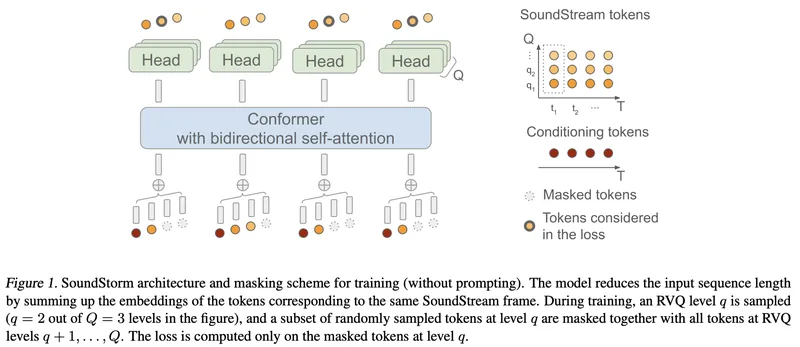
Soundstreamの残差ベクトル量子化コードにMaskGiTを適用し、オーディオドメインに適したConformerアーキテクチャを採用しています。
主な特徴は、高速かつ高品質なオーディオ生成能力で、わずか18ステップで約2秒の音声を生成可能です。
また、事前に訓練されたSoundStreamモデルを組み込むことで、生オーディオデータから直接学習し、最先端の音声を生成できます。
想定されるユーザーは、音声合成やオーディオ生成に関する研究者や開発者、特にPyTorch環境でのモデル開発や実験を行う方々です。
互換性・特徴
- Python
- PyTorch
- CLI
- Huggingface対応
- オーディオ生成
- AI/機械学習
基本情報
| ライセンス | MIT |
| Stars | 1,545 |
| Forks | 94 |
| カテゴリ | 音声生成 / TTS |
| アクティビティ | mid |
最新のissue
- どの韓国語の論文/音声モデルですか? (更新: 2025-04-27 / Which Korean Paper/Audio Model?)
- これは完了していますか? (更新: 2025-03-16 / Is this complete?)
- モデル text_to_semantic.load(‘/path/to/trained/model.pt’) はどこで入手できますか? (更新: 2025-03-03 / where I can find model text_to_semantic.load(‘/path/to/trained/model.pt’))
- 質問: 利用可能な事前学習済みモデルはありますか? (更新: 2024-11-26 / Question: Is there a pre-trained model we can use?)
- なぜここにこの行が必要なのですか? (更新: 2024-03-21 / why we need this line here?)
最新リリース: 0.6.1 (2025-04-24)