概要
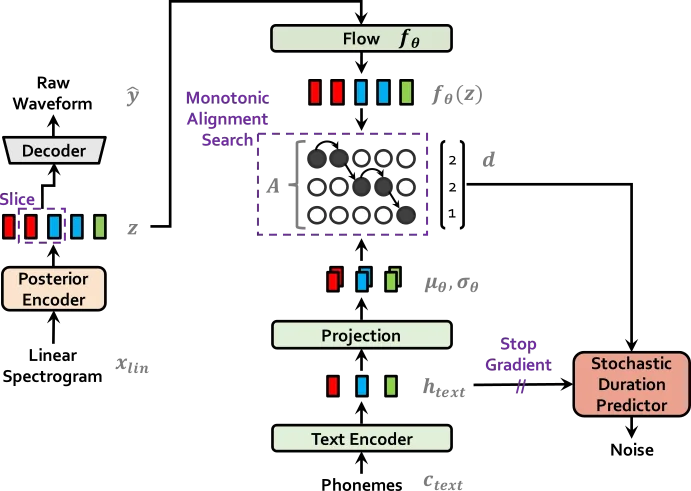
VITSは、エンドツーエンドのテキスト読み上げ(Text-to-Speech, TTS)システムであり、条件付き変分オートエンコーダと敵対的学習を組み合わせることで、従来の2ステージシステムを上回る自然な音声合成を実現します。
正規化フローによる変分推論と確率的duration predictorを用いることで、テキスト入力に対して多様なピッチとリズムで発話されるような、自然な「1対多」の関係を表現できるのが特徴です。
高品質な音声合成を研究・開発したい研究者や開発者、特にPythonでの機械学習モデル構築経験があり、表現力豊かなTTSシステムを求めるユーザーに適しています。
Colabでデモも利用可能です。
互換性・特徴
- Python
- TTS
- 研究プロジェクト
- CLI
- Colab対応
- GPU必須
基本情報
| ライセンス | MIT |
| Stars | 7,868 |
| Forks | 1,390 |
| カテゴリ | 音声生成 / TTS |
| アクティビティ | mid |
最新のissue
- 📋 ドキュメント改善提案 (更新: 2026-03-14 / 📋 Documentation Enhancement Suggestion)
- prior encoderにおけるvolume-preserving flowの設計選択に関する質問 (更新: 2026-01-22 / Question on the design choice of volume-preserving flow in the prior encoder)
- URDU言語向けPiple onnxファイルが必要 (更新: 2025-12-26 / Need Piple onnx file for URDU language)
- Python 3.10.12でのVITSコードの実行失敗 (更新: 2025-11-18 / VITS codes failed to run for Python 3.10.12)
- LJSPeechで必要なステップ数 (更新: 2025-11-13 / how many steps do we need in LJSPeech)