概要
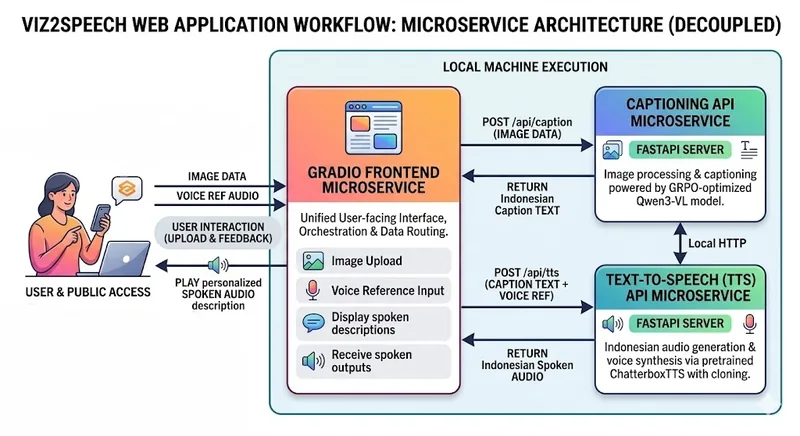
Viz2Speechは、インドネシアの視覚障害者のアクセシビリティを向上させるために開発された、画像から音声への変換エンジンです。
Qwen3-VLと強化学習で最適化されたVLMが画像を詳細なインドネシア語のテキストに変換し、Chatterbox-TTS-Indonesianがそれを自然な音声に合成します。
Gradioによるウェブインターフェースを通じて利用でき、ユーザーは画像をアップロードするだけで、その内容を音声で聞くことができます。
情報格差の解消を目的としています。
互換性・特徴
- Web UI
- AI/ML
- インドネシア語対応
- Python
基本情報
| ライセンス | MIT |
| Stars | 2 |
| Forks | 1 |
| カテゴリ | マルチモーダル |
| アクティビティ | low |