概要
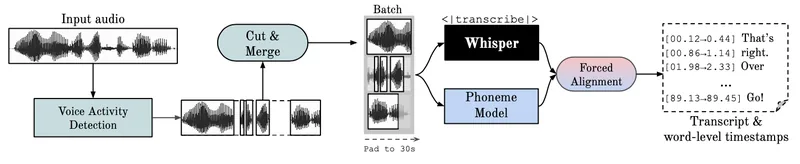
WhisperXは、OpenAIのWhisperモデルを基盤とした、単語レベルの正確なタイムスタンプと話者分離(Diarization)機能を備えた高速自動音声認識(ASR)ツールです。
特に、バッチ処理により70倍のリアルタイム転写速度を達成し、`faster-whisper`バックエンドを利用することでGPUメモリ消費を抑えながら高性能を発揮します。
`wav2vec2`によるアラインメントと`pyannote-audio`による話者分離を統合し、オリジナルのWhisperモデルの課題であった不正確なタイムスタンプやバッチ処理の欠如を克服しています。
大量の音声データを高速かつ高精度に文字起こしし、話者情報も付与したい開発者や研究者が主な想定ユーザーです。
互換性・特徴
- Python
- CLI
- GPU必須
- 自動音声認識 (ASR)
- 単語レベルタイムスタンプ
- 話者分離 (Diarization)
基本情報
| ライセンス | BSD-2-Clause |
| Stars | 22,914 |
| Forks | 2,331 |
| カテゴリ | ASR / 音声認識 |
| アクティビティ | high |
最新のissue
- Камаз (更新: 2026-07-04)
- Alignment fails when the same words are used in succession (更新: 2026-06-30)
最新リリース: v3.8.6 (2026-05-25)