


Redditでは、GPT-5.4とGPT-5.2のText Category Arena Rankingをめぐる投稿に対し、指標の読み方や実力差について議論が広がりました。
GPT-5.4 Text Category Arena Rankingの概要
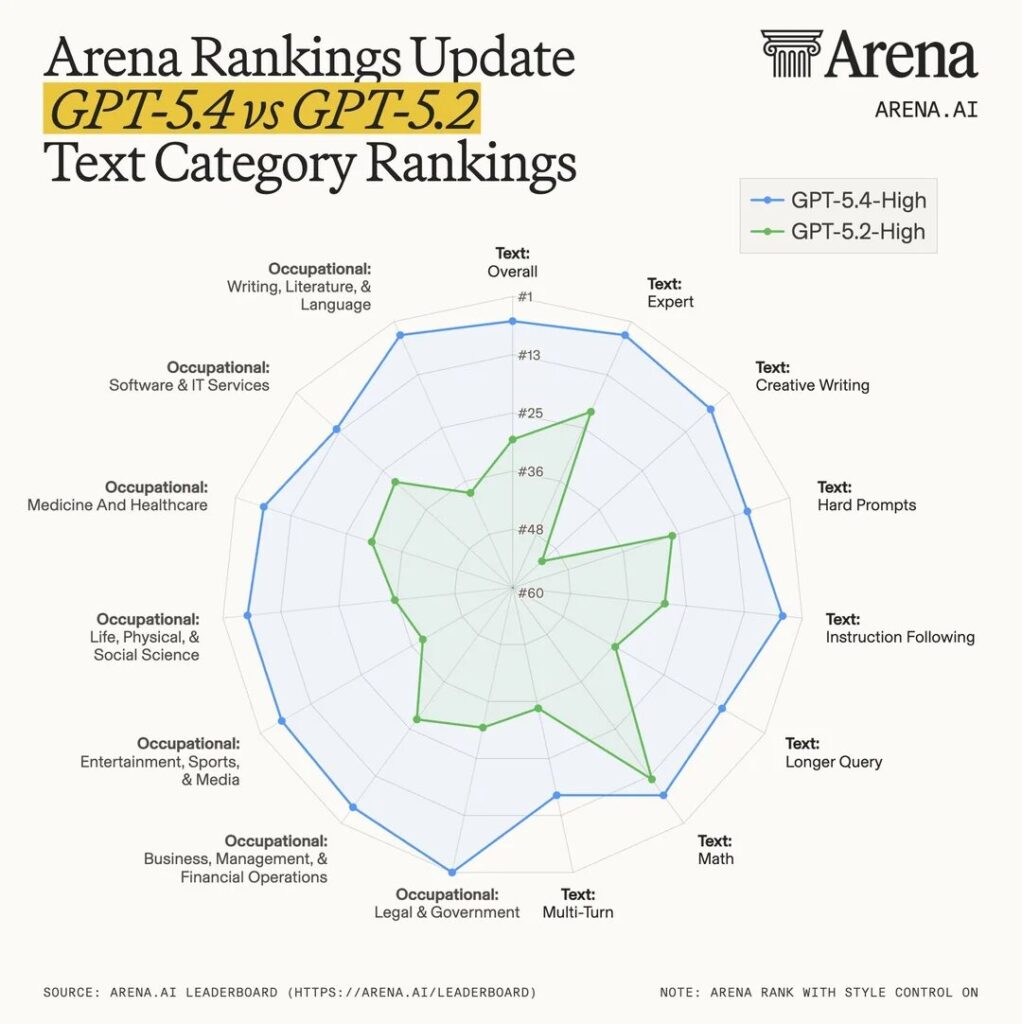
今回の話題は、GPT-5.4とGPT-5.2のText Category Arena Rankingを示すグラフに関するReddit上の議論です。
投稿内では、数値を百分率として見るべきか、順位として読むべきかという受け止め方の違いが見られた。
投稿者側は、これはカテゴリ内での順位を示すものだと理解している旨を説明していました。
別の参加者からも、100%は割合ではなく、そのカテゴリ内で最上位の位置を意味するという補足が出ています。

GPT-5.4に対するSNSの反応
指標の見方に関する反応
Redditでは、グラフの「100%」表記が何を意味するのか分かりにくいという声がありました。
一方で、これはモデル同士の相対的な順位を表すランキングであり、割合ではないという説明も複数存在。
そのため、数値の高さをそのまま性能差の大きさと受け取るのは適切ではない可能性があります。
GPT-5.4の改善を評価する声
反応の中には、GPT-5.4は従来どおり少し改善したように見えるという受け止めもありました。
ランキング上の位置を見て、順当に上がったと感じる利用者もいた形です。
上位カテゴリに入っていること自体を前向きに捉える空気も一部で確認されました。
GPT-5.4への懸念や不満
他方で、創作やテキスト生成の用途では期待ほどではなかったという感想も投稿されています。
長く詳細な回答になりやすく、場合によっては誤りも含むのではないかという不満も。
さらに、フロントエンド設計ではGeminiやClaudeの方が優れているとの意見もありました。
Codexアプリでのテキスト置換ミスが比較的多いとして、改善余地を指摘する声も見られます。
GPT-5.4 Text Category Arena Rankingから見える論点
今回のRedditで目立ったのは、ランキング上昇そのものよりも、指標の分かりやすさと実使用での満足度に関する議論です。
つまり、順位が高いことと、利用者が日常の創作や開発で強く評価することは必ずしも一致しないという論点でした。
特に creative writing や front-end design のような具体的用途では、他社モデルとの比較で厳しい見方も残っています。
そのため、この話題は単なる順位表の確認ではなく、評価指標と体感品質のずれを示す事例ともいえます。
参考リンク:
