概要
このプロジェクトは、PyTorchでContrastive Language-Image Pre-training (CLIP) をゼロから実装したものです。
「同じ意味を持つ画像とテキストを同じ埋め込み空間にマッピングする」というCLIPの核心概念を、InfoNCE損失関数を使ってコードで学ぶことを目的としています。
ResNet-20を画像エンコーダに、4層のTransformerエンコーダをテキストエンコーダに利用し、既存のfrom-scratchプロジェクトのコンポーネントを再利用している点が特徴です。
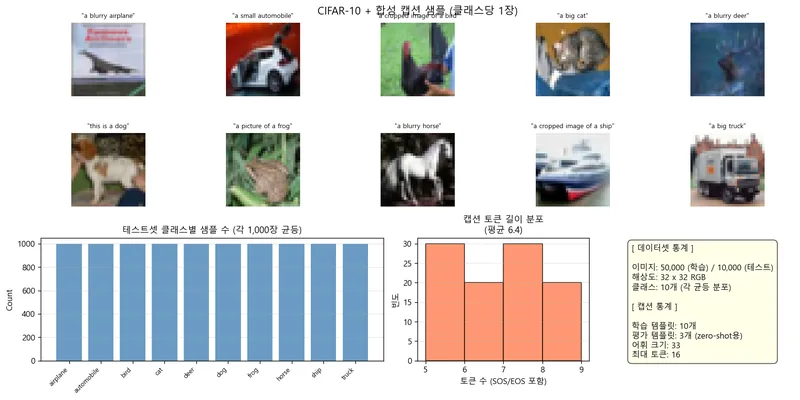
CIFAR-10データセットと合成キャプションを用いて学習を行い、学習していないテンプレートでも64.6%のzero-shot分類精度を達成しています。
これにより、モデルが単にキャプションを記憶するのではなく、意味を学習していることが示されています。
本ツールは、CLIPの内部動作やマルチモーダルモデルの実装に興味がある開発者や研究者に特に適しています。
互換性・特徴
- Python
- PyTorch
- GPU必須
- CLI
基本情報
| ライセンス | MIT |
| Stars | 1 |
| カテゴリ | マルチモーダル |
| アクティビティ | low |