マルチモーダル
HF gemma-4-31B-it
Gemma 4 31B itは、Google DeepMindのオープンウェイトな命令調整済みマルチモーダルモデルです。テキストと画像を入…
❤ 2.6k ↓ 8.7M apache-2.0 2026-05-07
マルチモーダル
HF clip-vit-large-patch14
CLIPのViT-L/14版を提供する研究向け画像・テキスト理解モデルです。画像と自然言語の対応を同一空間で学習し、事前…
❤ 2.0k ↓ 27.4M 2023-09-15
マルチモーダル
HF sam3
SAM 3は、画像と動画に対してプロンプト可能なセグメンテーションを行う統合基盤モデルです。短いテキスト、点、ボッ…
❤ 2.0k ↓ 3.1M other 2025-11-20
 マルチモーダル
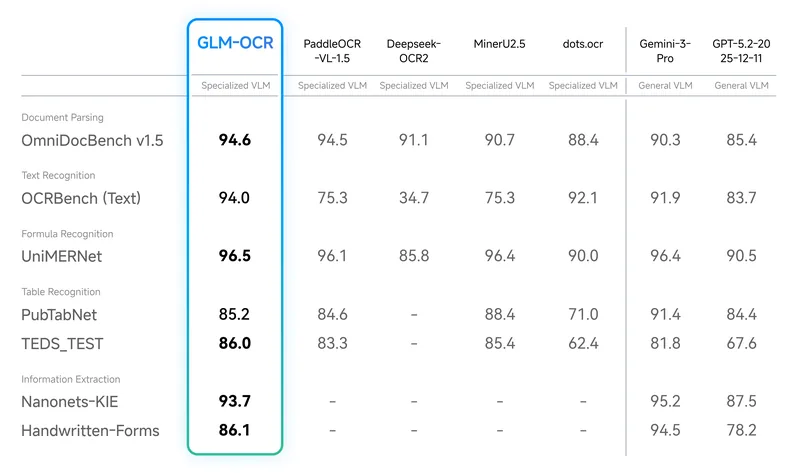
マルチモーダル HF GLM-OCR
GLM-OCRは、複雑な文書を高精度に読み取り・解析できるマルチモーダルOCRモデルです。数式、表、情報抽出まで対応し…
❤ 1.7k ↓ 8.2M mit 2026-04-14
 マルチモーダル
マルチモーダル HF Qwen3.6-35B-A3B
Qwen3.6-35B-A3Bは、Hugging Face Transformers形式で提供されるオープンウェイトの大規模マルチモーダル生成モデル…
❤ 1.7k ↓ 3.4M apache-2.0 2026-04-24
 マルチモーダル
マルチモーダル HF Gemma-4-31B-JANG_4M-CRACK
Gemma 4 31BベースのMLX向けマルチモーダル言語モデルで、画像入力を含む対話やコード生成、一般用途のアシスタント…
❤ 1.5k ↓ 156.1k gemma 2026-04-25
マルチモーダル HF Qwen3.6-27B
Qwen3.6-27Bは、Hugging Face Transformers形式で提供されるオープンウェイトの大規模マルチモーダルモデルです。画…
❤ 1.2k ↓ 2.0M apache-2.0 2026-04-24
マルチモーダル
HF clip-vit-base-patch32
openai/clip-vit-base-patch32は、画像とテキストを同じ埋め込み空間で比較し、任意のラベル文との類似度からゼロシ…
❤ 932 ↓ 21.6M 2024-02-29
 マルチモーダル
マルチモーダル HF vit-gpt2-image-captioning
`nlpconnect/vit-gpt2-image-captioning` は、画像を入力すると英語の説明文を自動生成できる画像キャプション生成モ…
❤ 929 ↓ 264.3k apache-2.0 2023-02-27
 マルチモーダル
マルチモーダル HF blip-image-captioning-base
SalesforceのBLIP画像キャプション生成モデルのベース版で、COCOデータセットで学習された画像説明向けの事前学習モ…
❤ 852 ↓ 2.4M bsd-3-clause 2025-02-03
 マルチモーダル
マルチモーダル HF siglip-so400m-patch14-384
SigLIP So400m Patch14 384は、Googleの画像と言語を結び付けるマルチモーダルモデルで、ゼロショット画像分類や画像…
❤ 674 ↓ 2.1M apache-2.0 2024-09-26
 マルチモーダル
マルチモーダル HF Qwen3.6-27B-GGUF
Qwen3.6-27B-GGUFは、Qwen3.6-27Bをもとにしたオープンウェイトの大規模言語・視覚対応モデルで、コード生成、リポジ…
❤ 622 ↓ 1.3M apache-2.0 2026-04-22
マルチモーダル
HF table-transformer-detection
Table Transformer(Table Detection向け)は、PubTables-1Mで学習されたDETR系の表検出モデルで、請求書や論文PDFな…
❤ 418 ↓ 3.4M mit 2023-09-06
マルチモーダル
HF BiomedCLIP-PubMedBERT_256-vit_base_patch16_224
BiomedCLIP-PubMedBERT_256-vit_base_patch16_224は、PubMed Central由来の1500万件の医用画像とキャプション対で事…
❤ 403 ↓ 883.3k mit 2025-01-14
 マルチモーダル
マルチモーダル HF sam3.1
SAM 3.1は、Metaの画像・動画向けプロンプト可能セグメンテーション基盤モデルSAM 3の改良版チェックポイントです。…
❤ 239 ↓ 227.3k other 2026-03-27
 マルチモーダル
マルチモーダル HF audio-flamingo-3-hf
Audio Flamingo 3は、音声・環境音・音楽を横断して理解し、文字起こし、音の内容把握、推論、対話まで行えるオープ…
❤ 183 ↓ 188.7k other 2026-04-13
マルチモーダル
HF nemotron-ocr-v2
Nemotron OCR v2は、複雑な実写画像や文書画像から文字を高精度かつ高速に抽出する、NVIDIAの商用利用可能な多言語OC…
❤ 176 ↓ 2.5k other 2026-04-28
マルチモーダル
GitHub DISCO
DISCOは、タンパク質配列と3次元構造を同時に設計できる拡散ベースのマルチモーダル生成モデルです。小分子リガンド…
★ 165 ⑂ 19 Apache-2.0 2026-04-09
マルチモーダル
HF LLaVA-Video-7B-Qwen2
LLaVA-Video-7B-Qwen2は、動画理解に特化した7B規模のマルチモーダルモデルです。画像・複数画像・動画を扱えますが…
❤ 126 ↓ 28.8k apache-2.0 2024-10-25
マルチモーダル
HF LLaVA-NeXT-Video-7B-hf
LLaVA-NeXT-Video-7B-hfは、画像と動画を一緒に理解して対話できるオープンソースのマルチモーダル生成モデルです。T…
❤ 123 ↓ 140.8k llama2 2025-11-11
マルチモーダル
GitHub ComfyUI-Ollama-Describer
ComfyUI-Ollama-Describerは、ComfyUIの拡張機能で、Ollamaの多様なLLMモデル(Gemma、Llava、Llama2/3、Mistralなど…
★ 116 ⑂ 23 MIT 2026-03-19
マルチモーダル
HF tipsv2-b14
TIPSv2 B/14は、画像とテキストを同じ埋め込み空間で扱えるGoogle系の視覚言語モデルです。画像全体の特徴量だけでな…
❤ 95 ↓ 12.1k apache-2.0 2026-04-14
 マルチモーダル
マルチモーダル HF Falcon-OCR
Falcon OCRは、画像から文書テキストを抽出する300Mパラメータ級の軽量OCR向けビジョン言語モデルです。通常の文字起…
❤ 93 ↓ 20.9k apache-2.0 2026-04-01
 マルチモーダル
マルチモーダル HF MOSS-VL-Instruct-0408
MOSS-VL-Instruct-0408は、OpenMOSS系の視覚言語モデルを教師あり微調整したマルチモーダル推論用チェックポイントで…
❤ 93 ↓ 3.3k apache-2.0 2026-04-22
 マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル