概要
SynthVisionは、医療画像VQA(Visual Question Answering)データセットの生成と、それを用いたVLM(Vision Language Model)のファインチューニングを行うためのPython製パイプラインです。
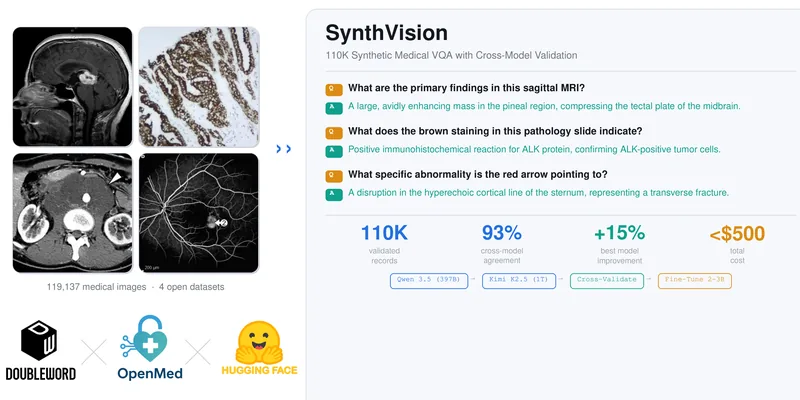
Qwen 3.5やKimi K2.5といったフロンティアVLMで119K枚の医療画像をアノテーションし、93%の高い合意率でクロスバリデーションされた110Kの訓練レコードを生成します。
これにより、2〜30億パラメータの小型VLMの性能を大幅に向上させ、特にQwen3.5-2Bモデルでは平均正解率が15.0%向上しました。
医療AI研究者やVLM開発者が、高品質な医療VQAデータセットを構築し、効率的にモデルをファインチューニングすることを想定しています。
Hugging Face Hubとの連携により、生成されたデータセットやファインチューニング済みモデルも公開されており、再利用が容易です。
互換性・特徴
- Python
- CLI
- GPU必須
- Hugging Face
- 医療AI
- データセット生成
基本情報
| Stars | 36 |
| Forks | 5 |
| カテゴリ | マルチモーダル |
| アクティビティ | low |