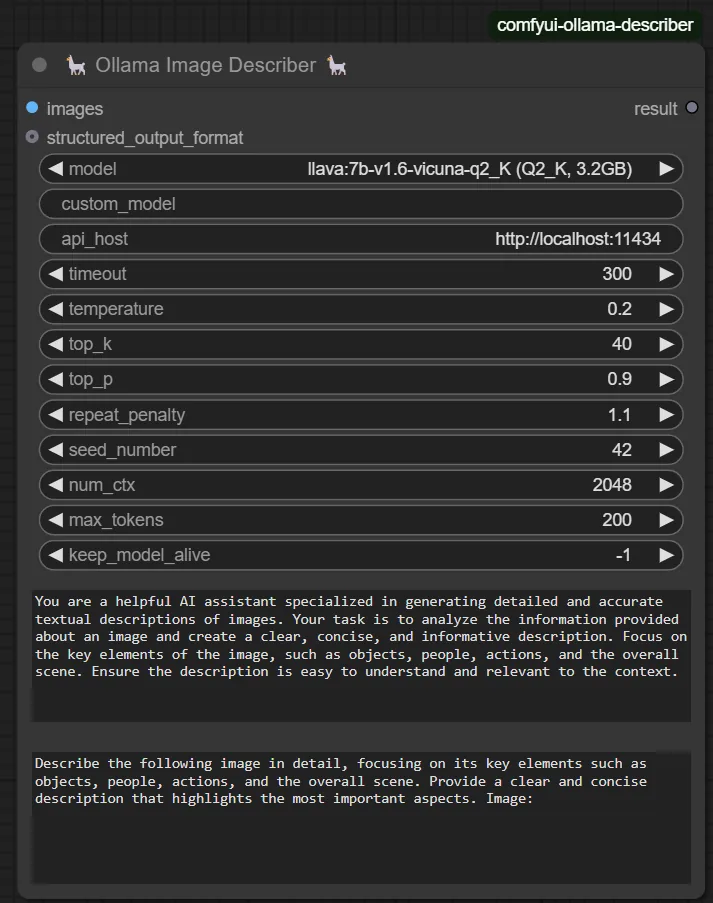
概要
ComfyUI-Ollama-Describerは、ComfyUIの拡張機能で、Ollamaの多様なLLMモデル(Gemma、Llava、Llama2/3、Mistralなど)を統合します。
画像やテキストの詳細な記述、自動キャプション生成、テキスト変換、JSONプロパティ抽出などの機能を備え、特にWeb検索能力を持つ自律エージェント(OllamaAgent)を特徴とします。
これにより、ComfyUIユーザーは、LLMを活用した複雑な画像・テキスト処理や情報探索ワークフローを構築できます。
開発者やクリエイターがOllamaの強力な機能をComfyUI環境で活用することを想定しています。
互換性・特徴
- ComfyUI対応
- Ollama
- LLM
- Python
- Web UI
- GPU推奨
基本情報
| ライセンス | MIT |
| Stars | 120 |
| Forks | 23 |
| カテゴリ | ComfyUI |
| アクティビティ | mid |
最新のissue
- no video describer (更新: 2026-06-19)
- Ollama Video Describerのnum_ctxウィジェット、デフォルト4096にも関わらず編集後に2048にクランプされる (更新: 2026-06-04 / Ollama Video Describer num_ctx widget clamps to 2048 after editing despite default being 4096)
- 画像記述子で思考を無効にする方法 (更新: 2026-03-23 / how to disable think in image describer?)
- Ollama Text Describerの例 (更新: 2025-10-03 / example Ollama Text Describer)
- 【純粋な情報】📚 ComfyUIの足りないマニュアルを作成:2000以上のプラグインをシンプルに解説 (更新: 2025-07-07 / 【纯干货】📚 I Built The Missing Manual for ComfyUI: 2000+ Plugins Explained Simply.)
GitHub: https://github.com/alisson-anjos/ComfyUI-Ollama-Describer