 LLM
LLM GitHub LLMs-from-scratch
このリポジトリは、書籍「Build a Large Language Model (From Scratch)」の公式コードベースです。GPTに似た大規模…
★ 98.0k ⑂ 15.0k NOASSERTION 2026-06-02
 ASR / 音声認識
ASR / 音声認識 GitHub voicebox
Voiceboxは、ElevenLabsやWisprFlowの機能を統合した、オープンソースのAI音声スタジオです。数秒の音声サンプルから…
★ 35.2k ⑂ 4.2k MIT 2026-06-28
 画像生成
画像生成 GitHub InvokeAI
Invokeは、Stable Diffusionモデルを活用し、プロフェッショナルから愛好家まで幅広いユーザーがビジュアルメディア…
★ 27.5k ⑂ 2.9k Apache-2.0 2026-06-29
 音声生成 / TTS
音声生成 / TTS GitHub index-tts
IndexTTS2は、感情豊かで再生時間の厳密な制御が可能な自己回帰型ゼロショットテキスト音声合成(TTS)モデルです。…
★ 21.4k ⑂ 2.6k NOASSERTION 2026-06-23
 3D / NeRF
3D / NeRF GitHub Meshroom
Meshroomは、複雑なデータ処理パイプラインを作成、管理、実行するためのオープンソースのノードベースのビジュアル…
★ 12.8k ⑂ 1.2k NOASSERTION 2026-06-27
 マルチモーダル
マルチモーダル GitHub X-AnyLabeling
X-AnyLabelingは、Segment Anythingなどの強力なAIモデルを活用し、データラベリングを効率化するツールです。自動ラ…
★ 9.6k ⑂ 1.0k GPL-3.0 2026-06-28
 ASR / 音声認識
ASR / 音声認識 GitHub inference
Xorbits Inference (Xinference) は、言語、音声認識、マルチモーダルモデルの提供を容易にする強力で多機能なライブ…
★ 9.4k ⑂ 837 Apache-2.0 2026-06-24
 音声生成 / TTS
音声生成 / TTS GitHub Bert-VITS2
Bert-VITS2は、多言語BERTをVITS2バックボーンに統合したテキスト読み上げ(TTS)システムです。このツールは、高度…
★ 8.8k ⑂ 1.3k AGPL-3.0 2026-06-22
 音楽生成
音楽生成 GitHub introtodeeplearning
MIT 6.S191「Introduction to Deep Learning」の公式コードとソフトウェアラボ資料を提供するリポジトリです。本コー…
★ 8.7k ⑂ 4.5k MIT 2026-01-04
 画像生成
画像生成 GitHub min-dalle
min(DALL·E)は、Boris Dayma氏のDALL·E Mini(メガウェイト版)を高速かつ最小限に移植したPyTorchベースの画像生成…
★ 3.5k ⑂ 249 MIT 2025-04-28
 ASR / 音声認識
ASR / 音声認識 HF whisper-large-v3-turbo
Whisper large-v3-turboは、OpenAIが提案する最先端の自動音声認識(ASR)および音声翻訳モデルであるWhisper large-…
❤ 3.1k ↓ 7.4M mit 2024-10-04
マルチモーダル HF gemma-4-31B-it
Gemma 4 31B itは、Google DeepMindのオープンウェイトな命令調整済みマルチモーダルモデルです。テキストと画像を入…
❤ 3.1k ↓ 11.1M apache-2.0 2026-06-03
マルチモーダル HF sam3
SAM 3は、画像と動画に対してプロンプト可能なセグメンテーションを行う統合基盤モデルです。短いテキスト、点、ボッ…
❤ 2.3k ↓ 1.7M other 2025-11-20
マルチモーダル HF Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive
Qwen3.6-35B-A3Bをベースに、拒否応答を極力外したHauhauCS製のGGUF配布モデルです。テキストに加えて画像・動画も扱…
❤ 2.3k ↓ 3.3M apache-2.0 2026-04-17
LLM GitHub how-to-train-your-gpt
このリポジリは、ChatGPTなどに使われている大規模言語モデル(LLM)をゼロから構築、学習、実行する方法を学ぶため…
★ 2.3k ⑂ 303 MIT 2026-06-23
 音声生成 / TTS
音声生成 / TTS GitHub audio-diffusion-pytorch
audio-diffusion-pytorchは、PyTorchで拡散モデルを用いてオーディオを生成するための多機能ライブラリです。無条件…
★ 2.1k ⑂ 177 MIT 2023-06-12
 動画生成
動画生成 GitHub make-a-video-pytorch
Make-A-Video Pytorchは、Meta AIが発表した最先端のテキストから動画を生成するモデル「Make-A-Video」をPyTorchで…
★ 2.0k ⑂ 184 MIT 2024-05-03
 ComfyUI
ComfyUI GitHub comfyui-mixlab-nodes
comfyui-mixlab-nodesは、ComfyUI向けにWebアプリ化、画面共有、音声認識・音声合成、GPT連携、3D生成などをまとめて…
★ 1.9k ⑂ 125 MIT 2026-06-04
 ComfyUI
ComfyUI GitHub ComfyUI-ReActor
ComfyUI向けの高速・簡単な顔交換ノード集で、画像内の顔を別の顔へ差し替えるワークフローをWeb UI上で構築できます…
★ 1.3k ⑂ 231 GPL-3.0 2026-05-12
 音声生成 / TTS
音声生成 / TTS GitHub tango
Tangoは、LLM(Flan-T5)によってガイドされる潜在拡散モデル(LDM)を用いた、テキストからオーディオを生成するツ…
★ 1.2k ⑂ 105 NOASSERTION 2025-07-29
マルチモーダル HF gemma-4-26B-A4B-it
Gemma 4 26B A4B itは、Google DeepMindのオープンウェイトなマルチモーダル指示調整モデルです。テキストと画像を入…
❤ 1.2k ↓ 13.1M apache-2.0 2026-06-03
 ComfyUI
ComfyUI GitHub ComfyUI-Frame-Interpolation
ComfyUI上で動画や連番画像の中間フレームを生成し、フレーム補間による滑らかな映像化を行うためのカスタムノード集…
★ 1.0k ⑂ 130 MIT 2026-03-29
マルチモーダル HF clip-vit-base-patch32
openai/clip-vit-base-patch32は、画像とテキストを同じ埋め込み空間で比較し、任意のラベル文との類似度からゼロシ…
❤ 963 ↓ 23.2M 2024-02-29
 ComfyUI
ComfyUI GitHub SeargeSDXL
Searge-SDXLは、ComfyUI向けのSDXL 1.0用カスタムノード拡張と統合ワークフローです。baseモデルとrefinerモデルを組…
★ 876 ⑂ 65 MIT 2024-05-22
 LLM
LLM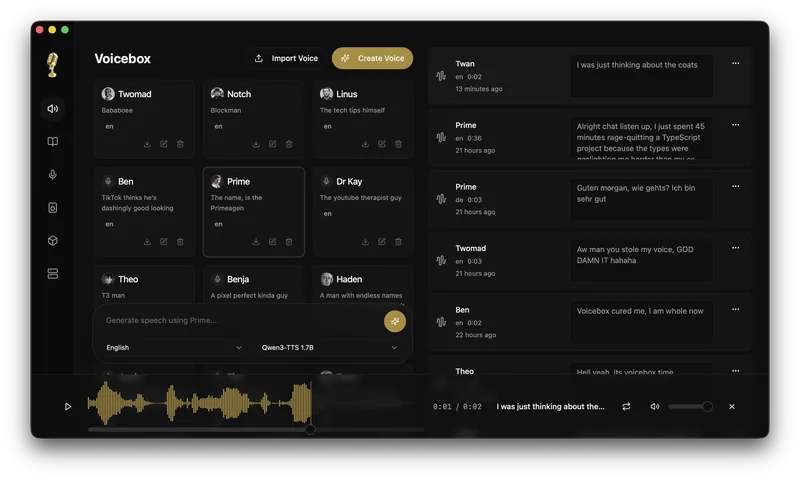 ASR / 音声認識
ASR / 音声認識 画像生成
画像生成 音声生成 / TTS
音声生成 / TTS 3D / NeRF
3D / NeRF マルチモーダル
マルチモーダル ASR / 音声認識
ASR / 音声認識 音声生成 / TTS
音声生成 / TTS 音楽生成
音楽生成 画像生成
画像生成 ASR / 音声認識
ASR / 音声認識 マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル LLM
LLM 音声生成 / TTS
音声生成 / TTS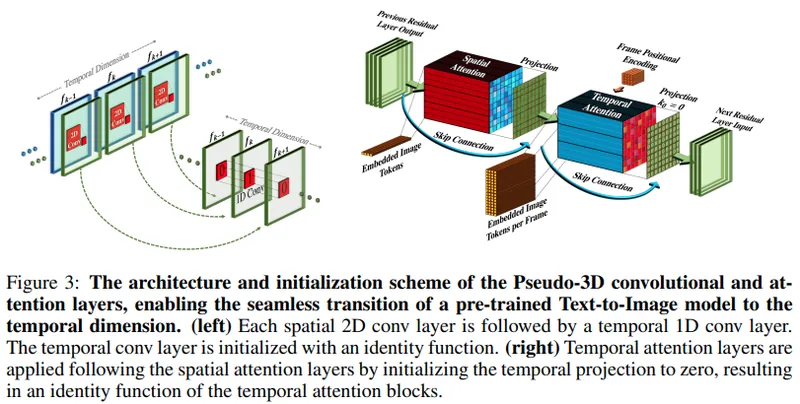 動画生成
動画生成 ComfyUI
ComfyUI ComfyUI
ComfyUI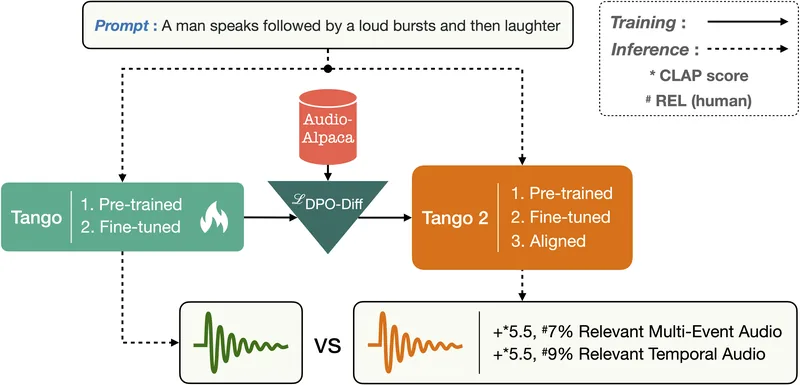 音声生成 / TTS
音声生成 / TTS マルチモーダル
マルチモーダル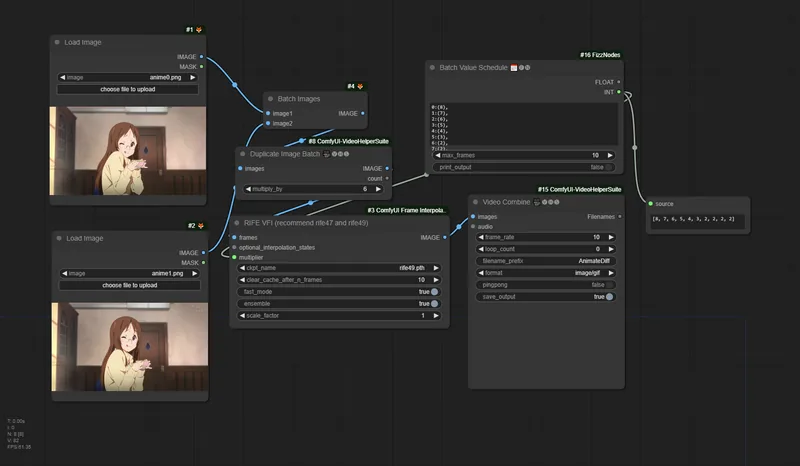 ComfyUI
ComfyUI マルチモーダル
マルチモーダル ComfyUI
ComfyUI