 画像生成
画像生成 HF Qwen3.5-9B-Claude-4.6-Opus-Reasoning-Distilled-GGUF
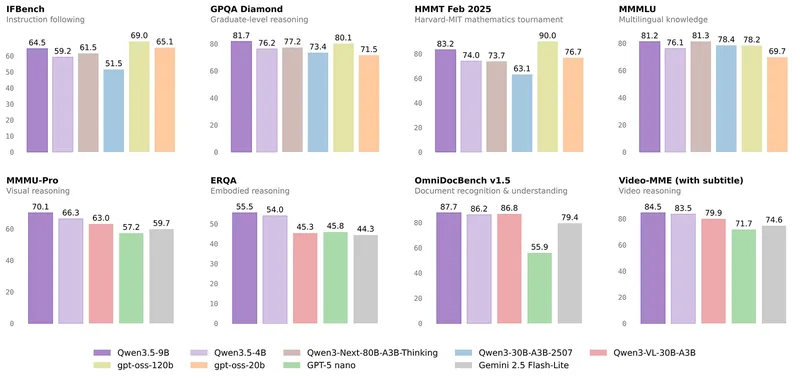
Qwen3.5-9Bをベースに、Claude 4.6 Opus由来の推論データを蒸留してSFT+LoRAで強化した推論特化モデルです。`<think>…
❤ 329 ↓ 187.1k apache-2.0 2026-04-06
 マルチモーダル
マルチモーダル HF BEN2
BEN2は、画像や動画から人物・物体の前景を高精度に切り抜き、背景除去やマスク生成を行うためのPython向けセグメン…
❤ 236 ↓ 24.7k mit 2025-12-31
 マルチモーダル
マルチモーダル HF audio-flamingo-3-hf
Audio Flamingo 3は、音声・環境音・音楽を横断して理解し、文字起こし、音の内容把握、推論、対話まで行えるオープ…
❤ 187 ↓ 263.1k other 2026-04-13
 マルチモーダル
マルチモーダル HF Qwen2-Audio-7B
Qwen2-Audio-7Bは、音声を入力として受け取り、内容理解や音声指示に基づく応答を行える大規模音声言語モデルです。…
❤ 172 ↓ 5.0k apache-2.0 2024-11-20
 マルチモーダル
マルチモーダル HF Qwen2-Audio-7B-GGUF
Qwen2-Audio-7B-GGUFは、Nexa-SDK上でローカル実行できる音声・テキスト対応のマルチモーダルAIモデルです。ASRを別…
❤ 171 ↓ 2.7k apache-2.0 2024-11-25
 マルチモーダル
マルチモーダル HF VibeVoice-ASR-HF
VibeVoice-ASR-HFは、Microsoftの長時間音声向け音声認識モデルをTransformers互換で使えるようにしたツールです。最…
❤ 155 ↓ 671.7k mit 2026-03-09
 動画生成
動画生成 HF Wan2.2-TI2V-5B-Diffusers
Wan2.2は、テキストや画像から高品質な動画を生成する先進的な大規模動画生成モデルです。MoEアーキテクチャにより効…
❤ 144 ↓ 107.3k apache-2.0 2025-08-09
マルチモーダル HF LLaVA-Video-7B-Qwen2
LLaVA-Video-7B-Qwen2は、動画理解に特化した7B規模のマルチモーダルモデルです。画像・複数画像・動画を扱えますが…
❤ 127 ↓ 19.0k apache-2.0 2024-10-25
動画生成 HF Wan2.1-T2V-1.3B-Diffusers
Wan2.1は、最先端のビデオ生成技術を提供するオープンな大規模ビデオ基盤モデルスイートです。テキストからビデオ、…
❤ 127 ↓ 162.2k apache-2.0 2025-04-04
 マルチモーダル
マルチモーダル HF LLaVA-NeXT-Video-7B-hf
LLaVA-NeXT-Video-7B-hfは、画像と動画を一緒に理解して対話できるオープンソースのマルチモーダル生成モデルです。T…
❤ 125 ↓ 160.0k llama2 2025-11-11
 動画生成
動画生成 HF Matrix-Game-3.0
Matrix-Game 3.0は、画像とテキストを入力に、長時間の一貫性を保った720pインタラクティブ動画をリアルタイム生成で…
❤ 123 ↓ 255 apache-2.0 2026-04-28
 マルチモーダル
マルチモーダル HF Falcon-OCR
Falcon OCRは、3億パラメータを持つ早期結合型ビジョン・言語モデルで、文書のOCR(光学文字認識)に特化しています…
❤ 119 ↓ 5.6k apache-2.0 2026-05-13
マルチモーダル HF tipsv2-b14
TIPSv2 B/14は、画像とテキストを同じ埋め込み空間で扱えるGoogle系の視覚言語モデルです。画像全体の特徴量だけでな…
❤ 112 ↓ 12.1k apache-2.0 2026-06-27
 マルチモーダル
マルチモーダル HF music-flamingo-2601-hf
Music Flamingoは、音楽や楽曲の理解に特化したNVIDIAの大規模音声言語モデルです。曲調、テンポ、キー、楽器構成、…
❤ 105 ↓ 188.9k other 2026-04-09
マルチモーダル HF music-flamingo-hf
Music Flamingoは、楽曲やインストゥルメンタル音源を対象に、ジャンル・テンポ・キー・楽器構成・雰囲気・歌詞や文…
❤ 99 ↓ 16.8k other 2026-04-04
 マルチモーダル
マルチモーダル HF MOSS-VL-Instruct-0408
MOSS-VL-Instruct-0408は、OpenMOSS系の視覚言語モデルを教師あり微調整したマルチモーダル推論用チェックポイントで…
❤ 97 ↓ 331 apache-2.0 2026-04-22
 画像生成
画像生成 HF PixelSmile
PixelSmileは、既存の顔画像に対して笑顔・喜びなどの表情を細かく編集するための画像生成・編集モデルです。Qwen-Im…
❤ 90 ↓ 747 apache-2.0 2026-05-08
 画像生成
画像生成 HF ddpm-cifar10-32
google/ddpm-cifar10-32は、CIFAR-10向けに学習済みのDDPM画像生成モデルです。Hugging Face Diffusersの`DDPMPipeli…
❤ 85 ↓ 23.0k apache-2.0 2023-08-03
 マルチモーダル
マルチモーダル HF MOSS-Audio-8B-Thinking
MOSS-Audio-8B-Thinkingは、音声・環境音・音楽を横断的に理解できるオープンソースの音声理解モデルです。文字起こ…
❤ 76 ↓ 5.2k apache-2.0 2026-06-11
ASR / 音声認識 HF wav2vec2-large-xlsr-53-russian
このリポジトリは、Jonatas Grosman氏が開発したロシア語音声認識用のWav2Vec2-large-xlsr-53モデルを提供します。Hu…
❤ 75 ↓ 3.2M apache-2.0 2022-12-14
マルチモーダル HF MOSS-Audio-4B-Instruct
MOSS-Audio-4B-Instructは、音声・環境音・音楽を統合的に理解し、テキストで応答するオープンソースの音声理解モデ…
❤ 73 ↓ 17.1k apache-2.0 2026-04-14
マルチモーダル HF MOSS-VL-Base-0408
MOSS-VL-Base-0408は、OpenMOSS系の画像・動画理解向けマルチモーダル基盤モデルです。4段階の事前学習のみで構築さ…
❤ 61 ↓ 1.3k apache-2.0 2026-04-23
マルチモーダル HF acestep-transcriber
ACE-Step Transcriberは、ACE-Step v1.5の学習データ注釈に使われる多言語音声転写モデルです。話し声だけでなく歌声…
❤ 59 ↓ 9.7k mit 2026-02-03
 マルチモーダル
マルチモーダル HF audio-flamingo-next-hf
Audio Flamingo Nextは、音声・環境音・音楽をまとめて理解できるNVIDIAの大規模音声言語モデルです。音声Q&A、文字…
❤ 56 ↓ 8.0k other 2026-05-13
 画像生成
画像生成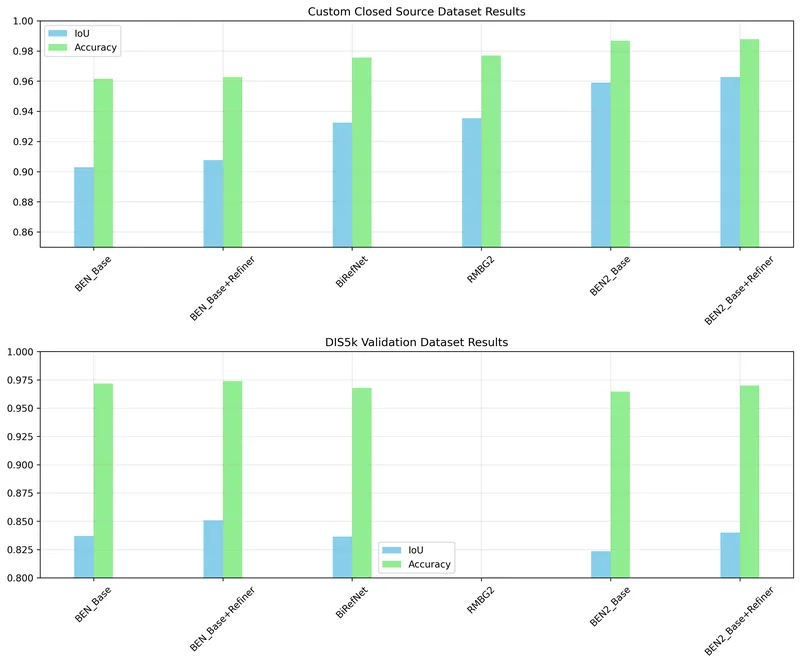 マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル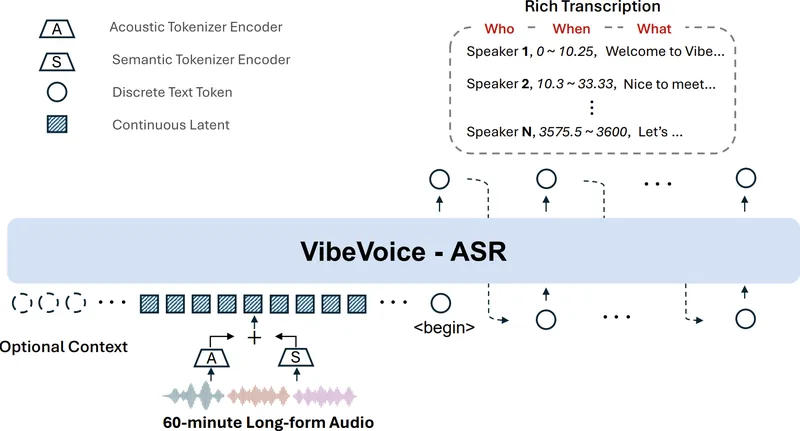 マルチモーダル
マルチモーダル 動画生成
動画生成 マルチモーダル
マルチモーダル 動画生成
動画生成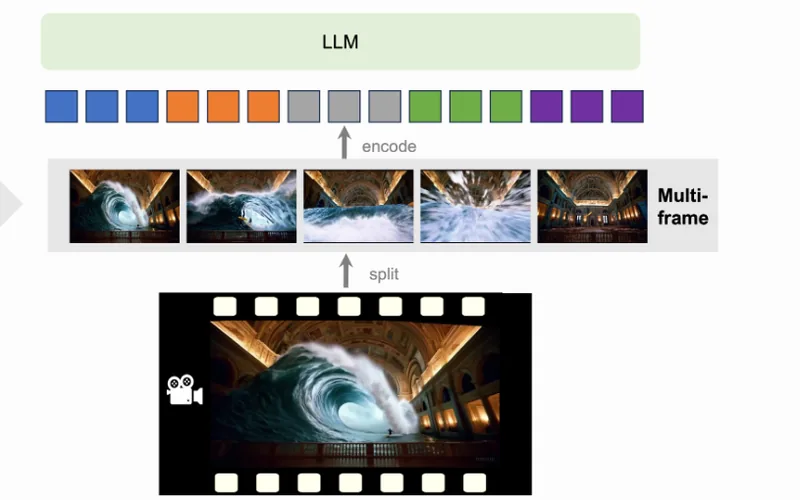 マルチモーダル
マルチモーダル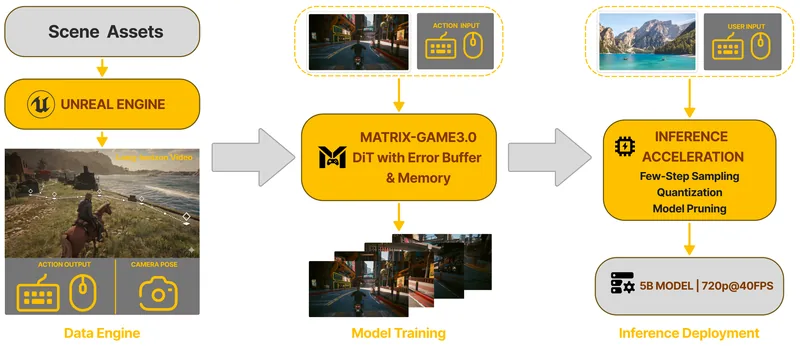 動画生成
動画生成 マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル 画像生成
画像生成 マルチモーダル
マルチモーダル ASR / 音声認識
ASR / 音声認識 マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル