 ASR / 音声認識
ASR / 音声認識 HF whisper-large-v3-turbo
Whisper large-v3-turboは、OpenAIが提案する最先端の自動音声認識(ASR)および音声翻訳モデルであるWhisper large-…
❤ 3.1k ↓ 7.4M mit 2024-10-04
マルチモーダル HF gemma-4-31B-it
Gemma 4 31B itは、Google DeepMindのオープンウェイトな命令調整済みマルチモーダルモデルです。テキストと画像を入…
❤ 3.1k ↓ 11.1M apache-2.0 2026-06-03
マルチモーダル HF sam3
SAM 3は、画像と動画に対してプロンプト可能なセグメンテーションを行う統合基盤モデルです。短いテキスト、点、ボッ…
❤ 2.3k ↓ 1.7M other 2025-11-20
マルチモーダル HF Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive
Qwen3.6-35B-A3Bをベースに、拒否応答を極力外したHauhauCS製のGGUF配布モデルです。テキストに加えて画像・動画も扱…
❤ 2.3k ↓ 3.3M apache-2.0 2026-04-17
マルチモーダル HF gemma-4-26B-A4B-it
Gemma 4 26B A4B itは、Google DeepMindのオープンウェイトなマルチモーダル指示調整モデルです。テキストと画像を入…
❤ 1.2k ↓ 13.1M apache-2.0 2026-06-03
マルチモーダル HF clip-vit-base-patch32
openai/clip-vit-base-patch32は、画像とテキストを同じ埋め込み空間で比較し、任意のラベル文との類似度からゼロシ…
❤ 963 ↓ 23.2M 2024-02-29
マルチモーダル HF Gemma-4-E4B-Uncensored-HauhauCS-Aggressive
Gemma 4 E4B-IT をベースに、応答拒否を大幅に外した GGUF 量子化モデルの配布ページです。Aggressive 版は安全制限…
❤ 845 ↓ 580.7k gemma 2026-04-06
 画像生成
画像生成 HF BFS-Best-Face-Swap
BFS(Best Face Swap)は、Qwen Image Edit 2509/2511およびFlux 2 Klein 4b/9b向けに作られた顔・頭部差し替え用のL…
❤ 642 ↓ 106.6k mit 2026-03-08
マルチモーダル HF Qwen2-Audio-7B-Instruct
Qwen2-Audio-7B-Instructは、音声入力を受けて会話や解析を行えるQwen系の音声対応大規模言語モデルです。テキストな…
❤ 540 ↓ 673.6k apache-2.0 2025-01-12
マルチモーダル HF segformer_b2_clothes
このツールは、Hugging Faceの`mattmdjaga/segformer_b2_clothes`リポジトリで提供されるSegFormer B2モデルであり、…
❤ 501 ↓ 148.7k other 2025-09-19
マルチモーダル HF Qwen3.6-27B-Uncensored-HauhauCS-Aggressive
Qwen3.6-27Bをベースに、応答拒否を抑えたGGUF配布モデルです。Aggressive版は過激な指示でも前置きや言い訳を減らし…
❤ 473 ↓ 548.9k apache-2.0 2026-04-24
マルチモーダル HF BiomedCLIP-PubMedBERT_256-vit_base_patch16_224
BiomedCLIP-PubMedBERT_256-vit_base_patch16_224は、PubMed Central由来の1500万件の医用画像とキャプション対で事…
❤ 411 ↓ 724.6k mit 2025-01-14
 マルチモーダル
マルチモーダル HF BEN2
BEN2は、画像や動画から人物・物体の前景を高精度に切り抜き、背景除去やマスク生成を行うためのPython向けセグメン…
❤ 236 ↓ 24.7k mit 2025-12-31
 マルチモーダル
マルチモーダル HF audio-flamingo-3-hf
Audio Flamingo 3は、音声・環境音・音楽を横断して理解し、文字起こし、音の内容把握、推論、対話まで行えるオープ…
❤ 187 ↓ 263.1k other 2026-04-13
マルチモーダル HF Qwen2-Audio-7B
Qwen2-Audio-7Bは、音声を入力として受け取り、内容理解や音声指示に基づく応答を行える大規模音声言語モデルです。…
❤ 172 ↓ 5.0k apache-2.0 2024-11-20
 マルチモーダル
マルチモーダル HF Falcon-OCR
Falcon OCRは、3億パラメータを持つ早期結合型ビジョン・言語モデルで、文書のOCR(光学文字認識)に特化しています…
❤ 119 ↓ 5.6k apache-2.0 2026-05-13
 マルチモーダル
マルチモーダル HF music-flamingo-2601-hf
Music Flamingoは、音楽や楽曲の理解に特化したNVIDIAの大規模音声言語モデルです。曲調、テンポ、キー、楽器構成、…
❤ 105 ↓ 188.9k other 2026-04-09
マルチモーダル HF music-flamingo-hf
Music Flamingoは、楽曲やインストゥルメンタル音源を対象に、ジャンル・テンポ・キー・楽器構成・雰囲気・歌詞や文…
❤ 99 ↓ 16.8k other 2026-04-04
マルチモーダル HF yolos-small
YOLOS (small-sized)は、Vision Transformerを基盤とした物体検出モデルです。このモデルはDETRロスを用いてCOCO 201…
❤ 95 ↓ 728.1k apache-2.0 2024-05-08
 画像生成
画像生成 HF ddpm-cifar10-32
google/ddpm-cifar10-32は、CIFAR-10向けに学習済みのDDPM画像生成モデルです。Hugging Face Diffusersの`DDPMPipeli…
❤ 85 ↓ 23.0k apache-2.0 2023-08-03
 マルチモーダル
マルチモーダル HF MOSS-Audio-8B-Thinking
MOSS-Audio-8B-Thinkingは、音声・環境音・音楽を横断的に理解できるオープンソースの音声理解モデルです。文字起こ…
❤ 76 ↓ 5.2k apache-2.0 2026-06-11
ASR / 音声認識 HF wav2vec2-large-xlsr-53-russian
このリポジトリは、Jonatas Grosman氏が開発したロシア語音声認識用のWav2Vec2-large-xlsr-53モデルを提供します。Hu…
❤ 75 ↓ 3.2M apache-2.0 2022-12-14
マルチモーダル HF MOSS-Audio-4B-Instruct
MOSS-Audio-4B-Instructは、音声・環境音・音楽を統合的に理解し、テキストで応答するオープンソースの音声理解モデ…
❤ 73 ↓ 17.1k apache-2.0 2026-04-14
 マルチモーダル
マルチモーダル HF audio-flamingo-next-hf
Audio Flamingo Nextは、音声・環境音・音楽をまとめて理解できるNVIDIAの大規模音声言語モデルです。音声Q&A、文字…
❤ 56 ↓ 8.0k other 2026-05-13
 ASR / 音声認識
ASR / 音声認識 マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル 画像生成
画像生成 マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル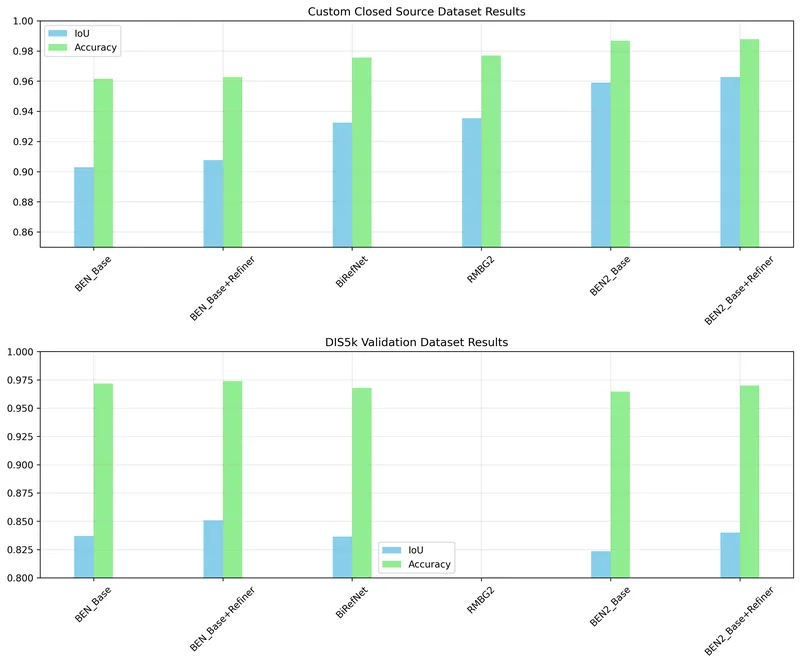 マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル 画像生成
画像生成 マルチモーダル
マルチモーダル ASR / 音声認識
ASR / 音声認識 マルチモーダル
マルチモーダル マルチモーダル
マルチモーダル